创新 • 创优 • 创见
一、什么是大数据
大数据(Big Data)最早是由麦肯锡(Mckinsey& Company)在《大数据:创新、竞争或和生产力的下一个前沿领域》报告中首次提出的概念,由于大数据超过传统数据库系统处理能力,常规软件工具无法在一定时间范围内对数据进行获取管理,因此需要通过大数据技术对海量数据进行处理分析,为决策提供强有力的数据支撑。
大数据处理关键技术一般包括:大数据采集、大数据预处理、大数据存储及管理、大数据分析及挖掘、大数据展现和应用。
二、大数据的特点
一般意义上的大数据是指海量的单一类型的数据或多元化多来源的数据。
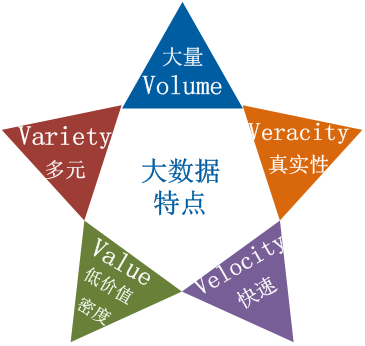
大数据具有5V特点(IBM提出):Volume(大量)、Variety(多元)、Value(低价值密度)、Velocity(快速)、Veracity(真实性)。
Volume(大量):数据的采集,计算,存储量都非常的庞大。
Variety(多元):数据的种类和来源多样化。种类包括结构化、半结构化和非结构化数据等,常见的来源有:网络日志、音频、视频、图片等等。
Value(低价值密度):数据价值密度相对较低,犹如浪里淘金,百炼成钢般才能获取到大量信息中的部分有价值的信息。
Velocity(高速):数据增长速度快,处理速度也快,获取数据的速度也快。
Veracity(真实性):数据的准确性和可信赖度,即数据的质量。
三、大数据技术在智能调度云系统的应用
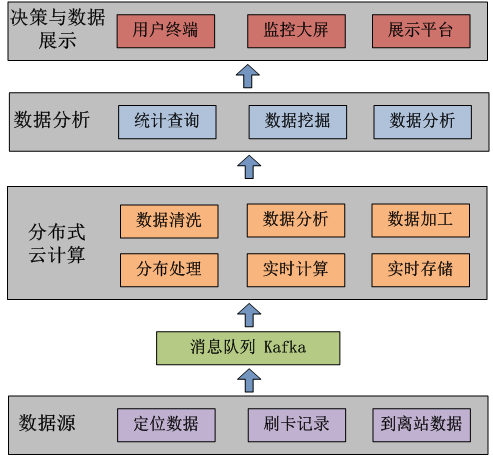
大数据分析常和云计算联系在一起,济南公交智能调度云系统云存储和云分析的运行需要巨大的计算和存储资源,采用Hadoop、Spark、云存储、云计算等分布式处理方式实时分析海量的定位数据,同时采用MapReduce模型技术用于大规模数据集的并行运算,实现了智能化、高效率的计算和分析。
Hadoop是一个分布式计算平台,可以在Hadoop上开发和运行处理海量数据的应用程序,Hadoop生态系统主要由HDFS、MapReduce、Hbase、Zookeeper、Oozie、Pig、Hive等核心组件构成,高可靠、高扩展、高有效、高容错等特性使Hadoop成为最流行的大数据分析系统。Spark提供强大的内存计算引擎,几乎涵盖了所有典型的大数据计算模式,包括迭代计算、批处理计算、内存计算、流式计算(Spark Streaming)、数据查询分析计算(Shark)以及图计算(GraphX)。Spark支持分布式数据集上的迭代式任务,可以在Hadoop文件系统上与Hadoop一起运行。
通过对定位数据分析,并结合乘车刷卡记录,对客流、运营状况等进行全面分析,分析运量与运力的匹配,分析运行的周转时间,分析运营的均衡性,分析挖掘数据存在的趋势和可能性,为线网优化评估提供决策支持。
随着人工智能的发展,数据分析和精准算法结合起来,必将成为公交管理决策的有力工具,为公交智慧化、精准化、便捷化、安全化提供重要技术支撑。





