|
2024年7月11-13日,2024中国汽车论坛在上海嘉定举办。本届论坛以“引领新变革,共赢新未来”为主题,由“闭门峰会、大会论坛、10多场主题论坛、9场重磅发布、主题参观活动”等多场会议和若干配套活动构成,各场会议围绕汽车行业热点重点话题,探索方向,引领未来。其中,在7月12日下午举办的“主题论坛一:第六届全球汽车技术发展领袖峰会”上,地平线总裁陈黎明发表精彩演讲。以下内容为现场演讲实录:

上午对业界谈得比较多的自动驾驶端到端大模型做了一些分享,同时把地平线在这方面的技术的积累和最新产品做了分享。本场论坛由于时间关系,不能展开,我想简单谈一下端到端大模型产品化。
端到端大模型的核心要素:算法、数据和算力、工程能力,这是我们认为在端到端大模型发展中非常重要的几个核心要素。对于端到端大模型,大家都谈得非常多,大家也都在做,在自动驾驶这个领域,它的落地我们认为不是一蹴而就的,是需要逐步去实现的,为什么这么讲?正如我上午所分享的,从规则驱动到数据驱动,技术迭代的“跷跷板效应”无法全面提升系统能力。规则驱动的软件1.0基于大量人工规则,系统上限低,下限可控;数据驱动的端到端系统,能够实现信息无损传递,系统上限高,而下限不可控。
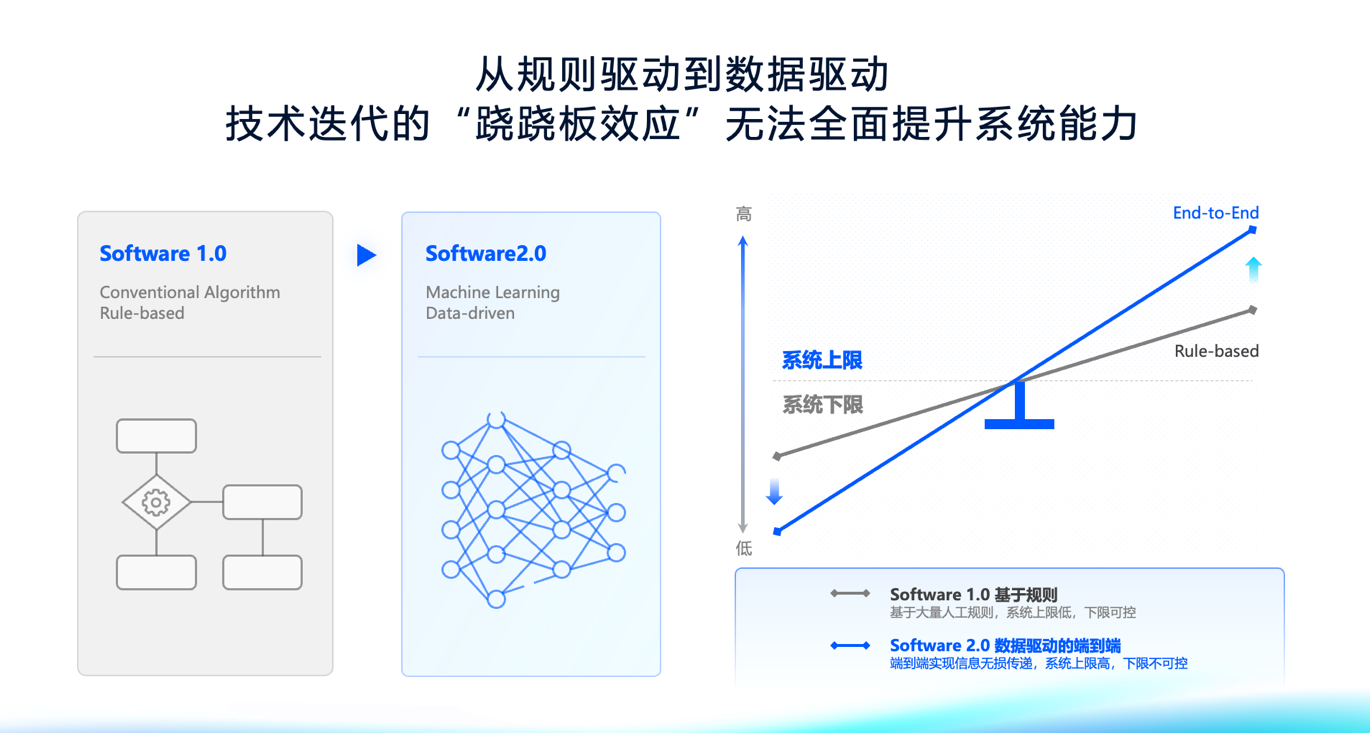
端到端大模型是基于一个概率模型训练,它有一个问题是对于比较简单,比较容易描述的场景,往往它的输出没有那么精确,它的底线比较低,安全的保障有一些concern。特斯拉在这块已经做得相当不错了,但是还没有完全解决这个问题,我们认为在目前缺乏足够数据的条件下,还是需要逐步实现端到端,一个模块、一个模块去替代,完成端到端的同时做好安全兜底,以这种比较坚实的工程基建和快速迭代的方式,能够一步步提升系统的性能上限,同时也能够保证系统性能的下限。这是一方面。
另一方面,整个技术还是在不断发展,包括模型本身、算法本身也在不断发展。我们之前用得比较多的神经网络都是卷积神经网络(CNN),目前比较流行的是Transformer,Transformer里面有特殊的算子,需要硬件去支持它。这就是为什么我们讲新的算法出现以后,前一代的芯片可能计算效能不能很好、很充分地支持最新的算法,这要求我们在硬件设计上更好地支持这些特殊的算子,使得整个计算效率更高。这是逐步实现的过程。
再一个我想讲的是数据。我们知道特斯拉今年推出的FSD V12.3版本让大家很惊艳,它在很短的时间里面用了一千万个样本视频,来训练它的自动驾驶这部分。一千万个样本是从100亿个样本里面提取出来的高质量数据,对于我们自动驾驶在中国落地的话,现在的数据积累远远不够。怎么得到这些数据,也是现在整个行业面临的挑战。主机厂的确有很多数据,但很多数据是不是真正高质量有用的?这是一个值得探讨的问题。因为对于特斯拉积累的100亿的数据,它是基于在标准传感器的框架下收集起来的,它有延续性,它在过去几年的积累可以继续用来训练它的一些最新的模型。
我们目前遇到的困难是很多车型和传感器的架构、传感器的布置和采用等都在不断变化,我们虽然收集了很多数据,但这些数据不是高质量地积累起来并且能够持续使用的,这块也是我们接下来不光是某个企业,而是整个行业要去探讨的问题。也就是说,主机厂和科技企业怎么能够协同起来解决这个问题,这是大家要共同探讨的。
我们认为随着自动驾驶的发展,2010年前后,当时的Google,现在的Waymo第一次把自动驾驶这个话题提出来,十几年间行业内各个企业大力投入研发,笃行不辍。虽然当前有不同的技术路线,但是地平线认为端到端是目前通往自动驾驶终局的更有效方案,需要大家不断地投入,来共同推动自动驾驶的落地。
我就分享这些,谢谢付会长。
(注:本文根据现场速记整理,未经演讲嘉宾审阅)
|