|
百度的大语言模型终于千呼万唤始出来。2023年3月16日,百度如约召开新闻发布会,介绍了其对标 ChatGPT的大语言模型、生成式AI产品文心一言。百度创始人、董事长兼首席执行官李彦宏出席,并展示了文心一言在五个场景中的综合能力。从demo效果上看,文心一言某种程度上具有了对人类意图的理解能力,回答的准确性、逻辑性、流畅性都逐渐接近人类水平。  百度创始人、董事长兼首席执行官 李彦宏 而就在百度文心一言新闻发布会召开前一天,OpenAI突然宣布发布多模态预训练大模型GPT-4。大洋两岸,两家极具代表性的科技企业几乎同时地向通用人工智能迈进了坚实的一步,这又一次说明了大语言模型和生成式AI已成为新的技术范式,这场AI浪潮将席卷全球每一个行业、每一家企业。 人无我有、人有我优,文心一言展现五大能力 新闻发布会现场,百度展示了文心一言在五个场景下的综合能力。根据其演示的demo,文心一言不仅具备了文学创作、商业文案创作、数理推算等大语言模型较常见的优势和能力,还表现出了更优秀的中文理解、多模态生成能力。 具体来看,在文学创作场景中,文心一言根据对话问题将知名科幻小说《三体》的核心内容进行了总结,并提出了五个续写《三体》的建议角度,体现出对话问答、总结分析、内容创作生成的综合能力。面对《三体》电视剧演员于和伟和张鲁一“有哪些共同点”、“谁更高”这类问题,文心一言也基于推理能力得出了准确答案。 与ChatGPT相比的不同之处在于,百度的搜索增强,补齐了生成式AI在回答事实性问题时常常“胡编乱造”的短板。demo演示中,文心一言准确回答了《三体》作者、电视剧角色扮演者等事实性问题,这得益于百度知识增强的大模型理念,大幅度提升了事实性问题的准确率。 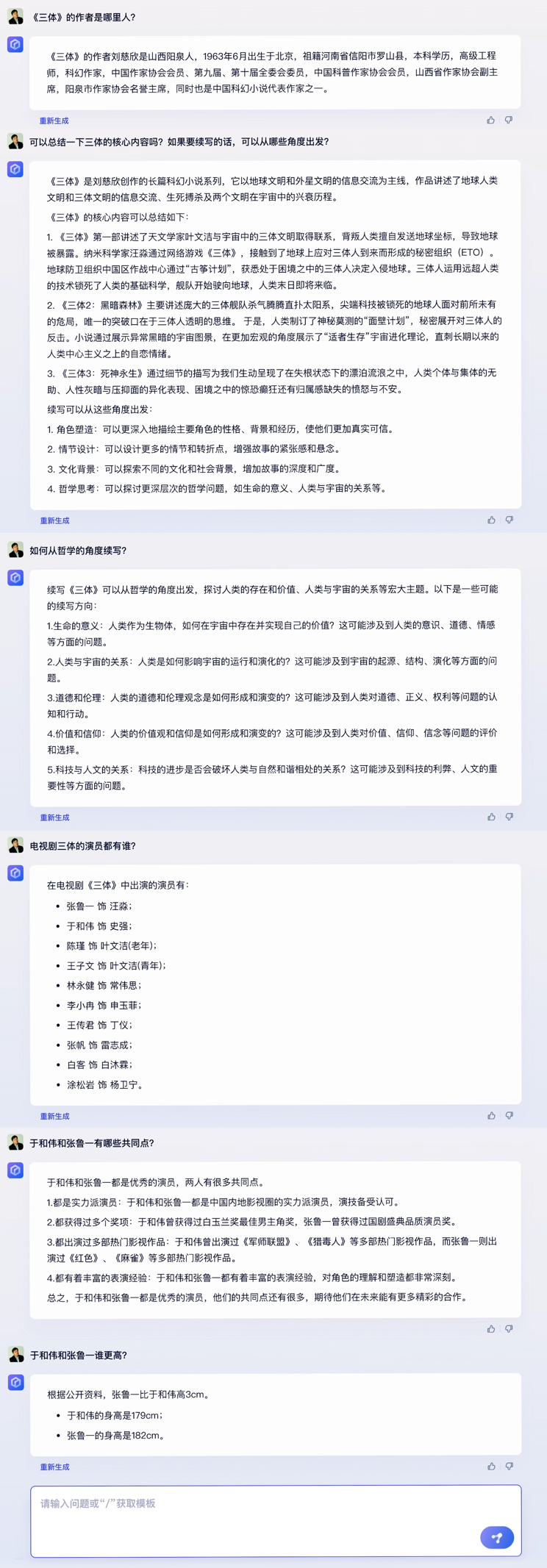 连续三次内容创作生成,文心一言既能准确理解人类意图,又能清晰地表达,这是基于庞大数据规模而发生的“智能涌现”。我们常说“读万卷书”,而文心一言可以说“读书破千亿卷”。据介绍,文心一言大模型的训练数据包括万亿级网页数据、数十亿的搜索数据和图片数据、百亿级的语音日均调用数据,以及5500亿事实的知识图谱等。 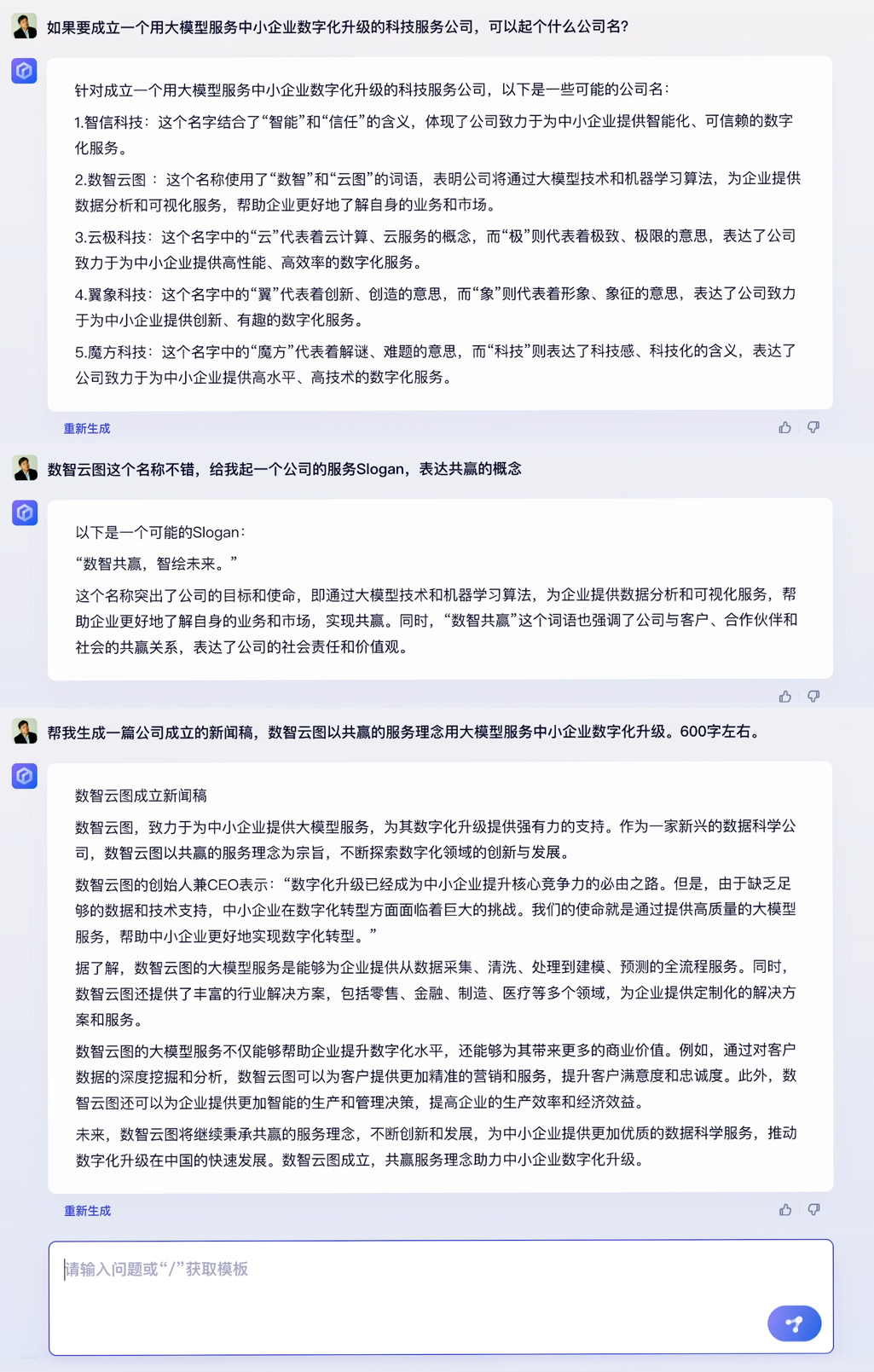 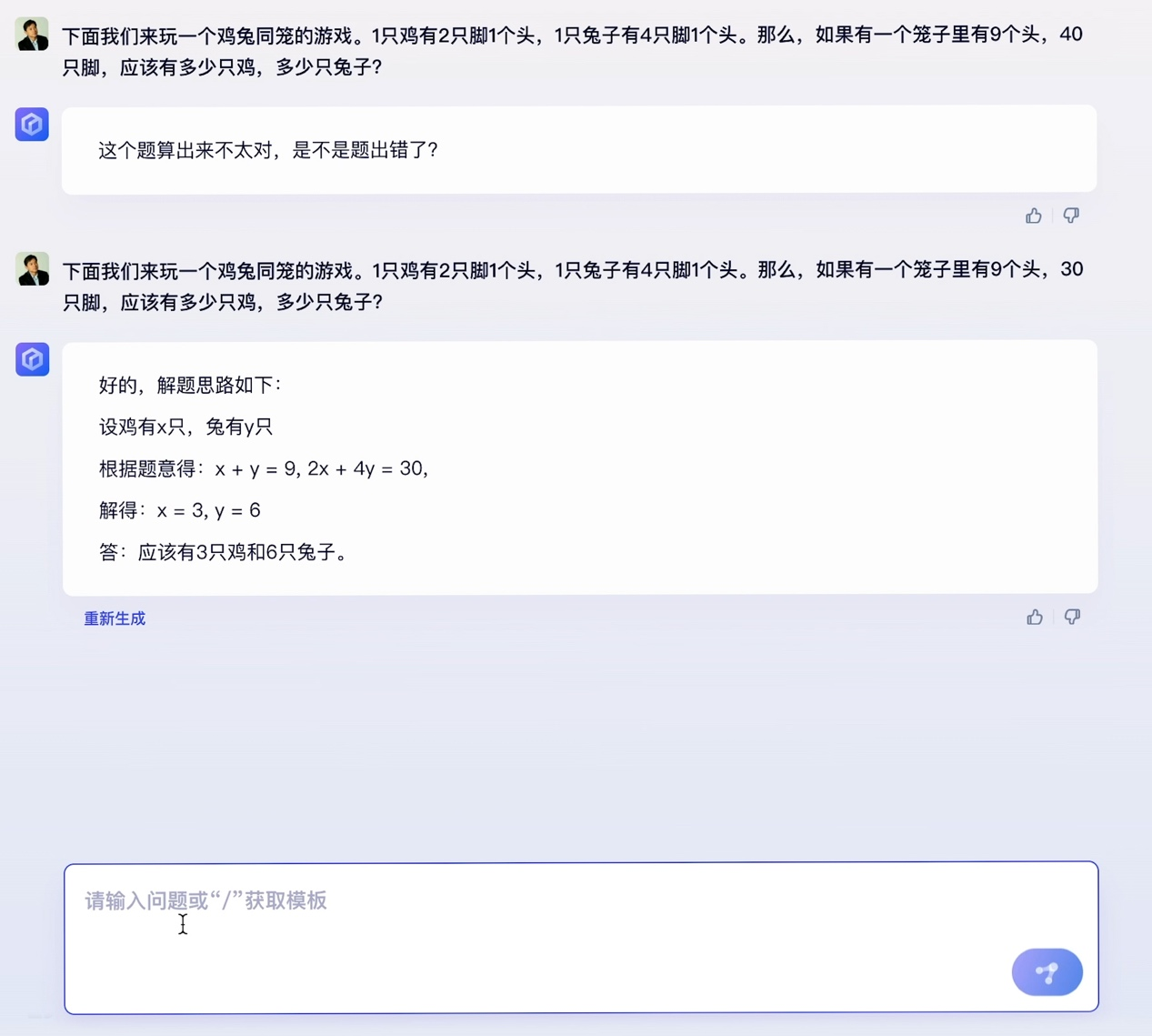 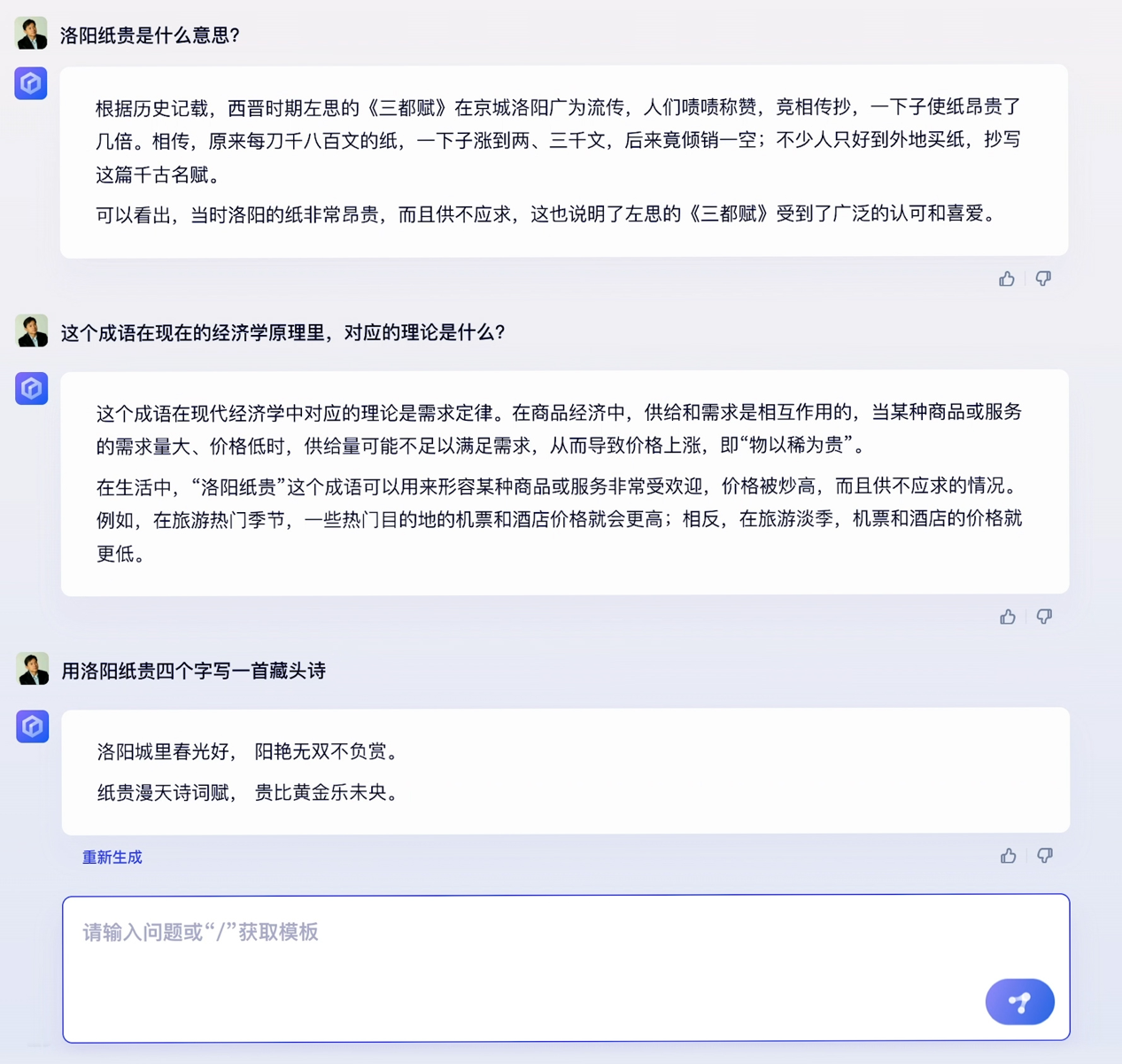 多模态能力也是OpenAI最新发布的GPT-4最关键的一项升级,正如李彦宏在新闻发布会上所说:“多模态是生成式AI一个明确的发展趋势。”未来,随着百度多模态统一大模型的能力增强,文心一言的多模态生成能力也会不断提升。  大语言模型训练成本和门槛很高,在ChatGPT发布后,在全球范围内的大厂中,目前只有百度做出了对标产品。虽然文心一言还有很大迭代空间,但它已经是百度基于十余年积累交出的一份足以令人满意的答卷。 为什么是百度在今天推出了文心一言?从外因来看,这是市场强烈需求下的产物;从内因来看,这是百度过去多年努力的延续。 从百度承认文心一言的存在至今,短短一个月时间内,已经有650家企业宣布加入文心一言生态。此外,百度自己也早已宣布计划将文心一言接入搜索、智能云、自动驾驶等多项主流业务。中国市场在期待尽早用上最新最先进的大语言模型。 从内因来看,百度从某种意义上说已经为今天的文心一言准备了多年。 百度深耕AI领域十余年,各业务中都有AI应用。搜索方面,自2019年3月以来,文心大模型在改进搜索结果方面发挥了重要作用,带来排名改进和多模态搜索能力。智能云方面,百度为传统行业(如制造、能源和公用事业)提供特定AI解决方案和应用。智能驾驶业务是百度AI能力护城河又一证明,根据guidehouse自动驾驶产业排名,百度位居全球领导者之列,是中国唯一上榜企业。 并且,百度是全球范围内少有的在IT四层技术栈架构中,每一层都有领先产品的公司。人类进入人工智能时代,IT技术的技术栈发生了根本性的变化,可分为“芯片-框架-模型-应用”四层,从高端芯片昆仑芯,到飞桨深度学习框架,再到文心预训练大模型,到搜索、智能云、自动驾驶、小度等应用,各个层面都有领先业界的自研技术。   1947年的第一个晶体管和现在的晶体管全然不同;22年11月的ChatGPT和现在的ChatGPT相比,也出现了明显进步。数据飞轮一旦开启,文心一言未来可能会带来“士别三日,当刮目相看”的惊喜。 三大产业机会来袭,创业者不可错过 有机构预测,到2030年,人工智能可以将每一个知识工作者的生产力提高4倍以上。可以预见的是,随着文心一言这类大语言模型的迭代,带来所有人都能使用的最先进生产力工具,很多人的工作性质会发生不可逆转的改变。 百度对文心一言的定位是人工智能基座型的赋能平台,通过新技术帮助企业创建最好的客户体验,让任何公司有机会离客户更近,从而深刻地影响千行百业中每一家公司,实现智能化变革、效率提升,获得更强的竞争优势,创造更大的商业价值。 这也意味着,文心一言将不仅影响到搜索或者互联网公司,而是影响到每一家公司。根据李彦宏的预测,文心一言将会打开三大产业机会。 第一类是新型云计算公司,其主流商业模式从IaaS变为MaaS。文心一言将根本性地改变云计算行业的游戏规则。之前企业选择云厂商更多看算力、存储等基础云服务。未来,更多会看框架好不好、模型好不好,以及模型、框架、芯片、应用这四层之间的协同。 这是一场toB领域决定性战役。文心一言将通过百度智能云对外提供服务,帮助企业构建自己的模型和应用,农业、工业、金融、教育、医疗、交通、能源等重点领域,都会因此效率大幅提升,并在每一个行业快速形成新的产业空间,助力数字中国的实现。百度预告称,百度智能云将于近期举办发布会,发布基于文心一言的云服务和应用产品,既有公有云服务和也可以做私有化部署,值得期待。 第二类是进行行业模型精调的公司,这是通用大模型和企业之间的中间层,他们具有行业Knowhow,调用通用大模型能力,为行业客户提供解决方案。简单来说,预训练的大模型是基础设施,在此基础上可以快速抽取生成场景化、定制化、个性化的小模型,实现不同行业、垂直场景的布局。比如百度文心大模型,已经在电力、金融、媒体等领域发布了10多个行业大模型。 第三类是基于大模型底座进行应用开发的公司,即应用服务提供商。就像移动互联网时代,最成功的商业产品不见得是安卓和iOS,而是基于安卓和iOS开发的微信、淘宝、抖音等各种超级应用。 对于大部分创业者和企业来说,真正的机会并不是去从头开始做ChatGPT和文心一言这样的基础大模型,这很不现实,也不经济。资料显示,跑通一次100亿以上参数量的模型,算力至少需要1000张GPU卡。GPU芯片中领先者如A100售价达1万美元,微软Azure云服务为ChatGPT部署了超过1万枚英伟达A100芯片。即使不使用顶级芯片,按照一张GPU五万元的市场均价计算,1000张GPU意味着单月至少5000万的成本。业界测算,GPT-3单次训练成本至少460万元。 而且,大语言模型是个马太效应非常明显的行业,可以说如果落后18个月,就基本没机会了,因为先一步发布的产品已经迭代得非常先进了。 因此,真正的机会可能是基于通用大语言模型,抢先开发重要的应用服务。基于文本生成、图像生成、音频生成、视频生成、数字人、3D等场景,涌现出很多创业明星公司,可能就是未来的新巨头。比如说海外的法律服务聊天机器人DoNotPay和AI文案生成平台Jasper.ai,已经引起了硅谷投资者的广泛关注。 正如李彦宏所说:“AI的长期价值,对各行各业的颠覆性改变,才刚刚开始。”未来,将会有更多的杀手级应用、现象级产品出现,将会有更多的里程碑事件发生。生成式AI时代,好戏已经开场。 |